Waving Robot
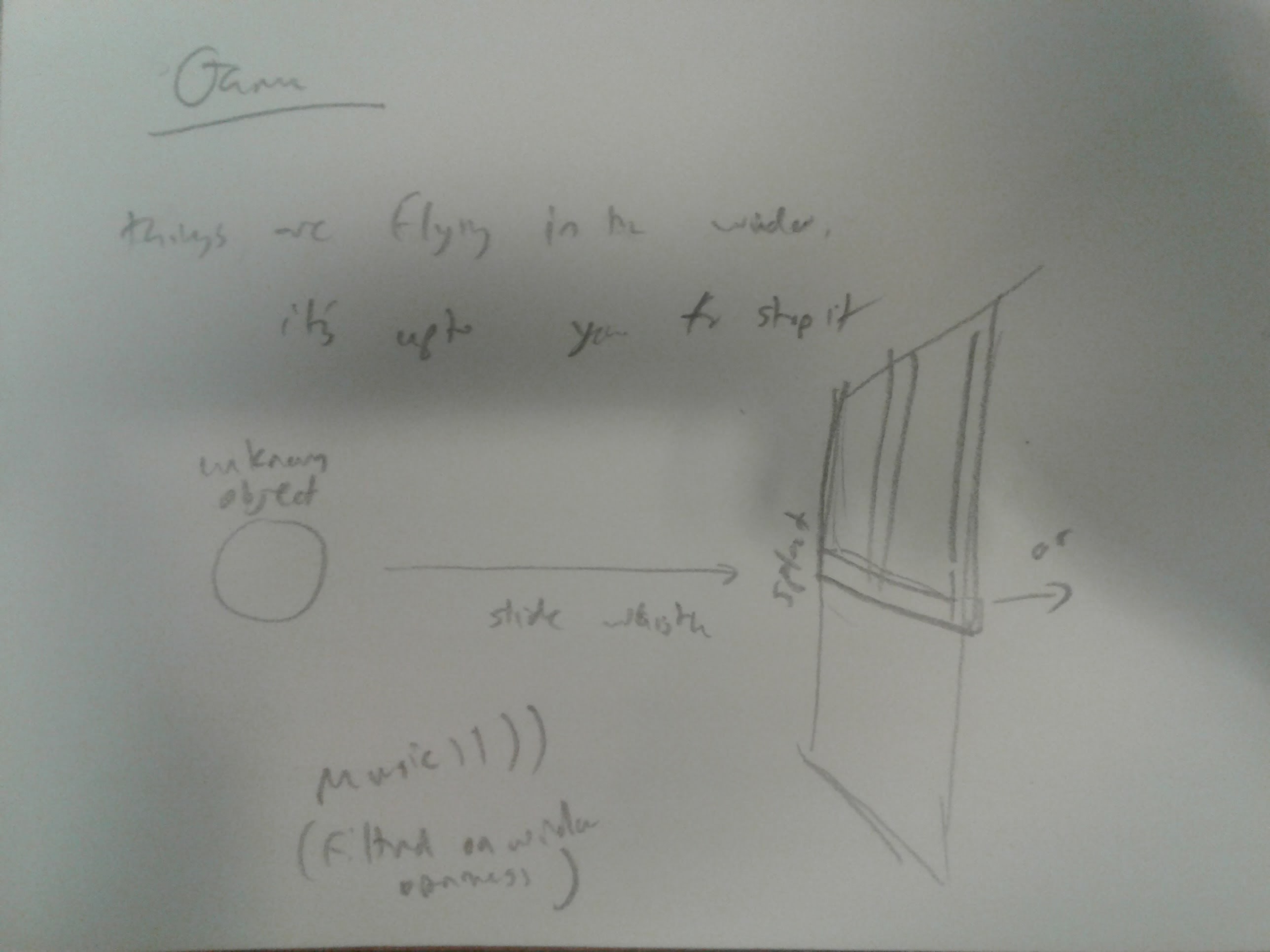
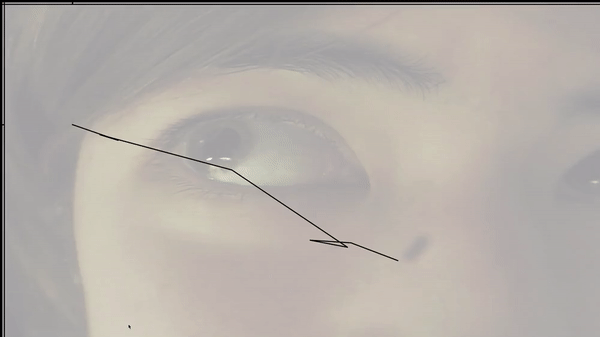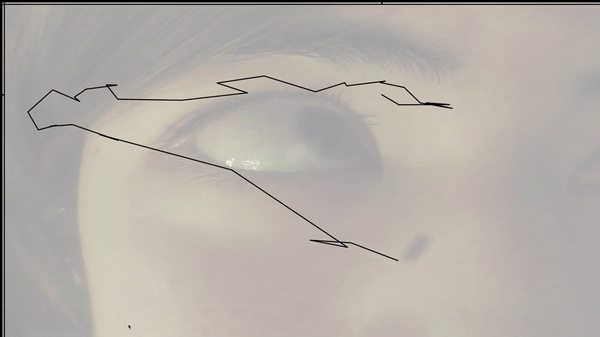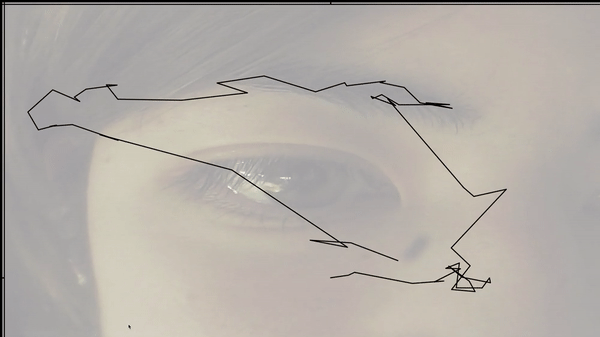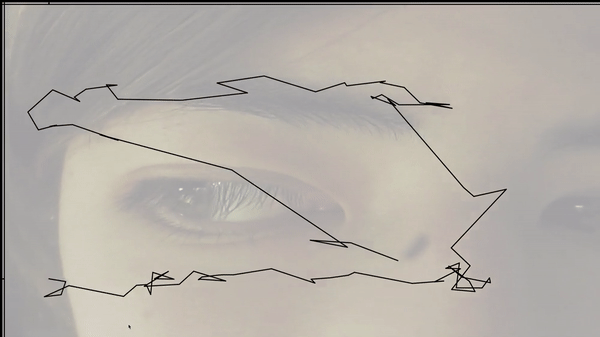
I really wanted this arm to be sticking out the side of my window:

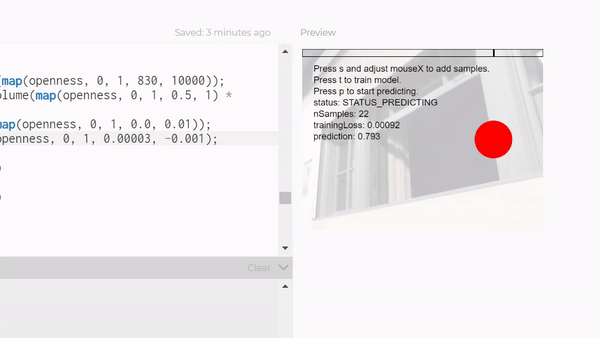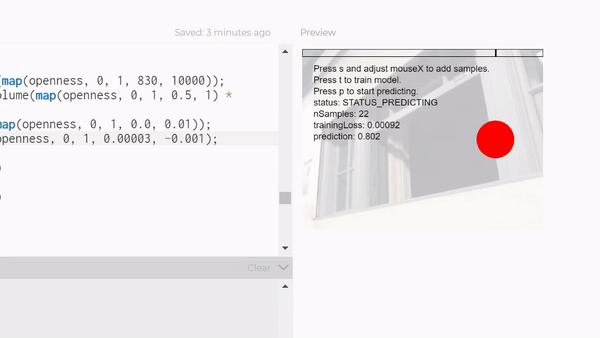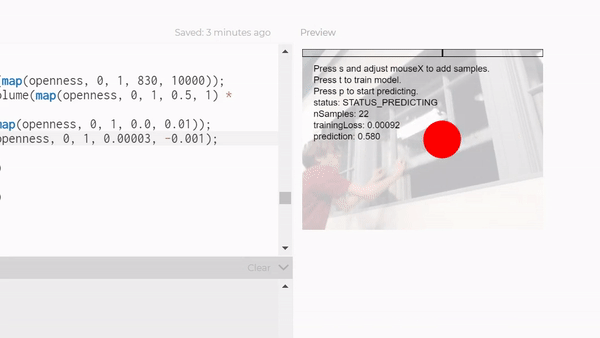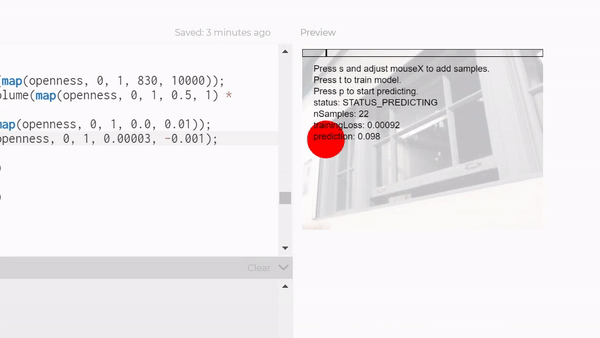
But I first tried to use the feature classifier to tell if people are walking towards or away, which really did not work at all. It could barely even tell if people were there or not. I spent a lot of time getting a large dataset before even really testing if it would work, so I wasted a lot of time on that.
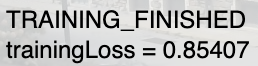
So then I switched to a KNN classifier mixed with posenet, to try to classify people walking in's poses. I think that might've worked with a bigger dataset, but I tried with around 150 examples for each category, and it just wasn't reliable, so I downsized again to it just recognizing me in my room. Hopefully I can extend it to outside, because I think it would be cool to have a robot that waves at people. I think I'll just hack it together rather than using a knn classifier, but for this project I had to train a model.
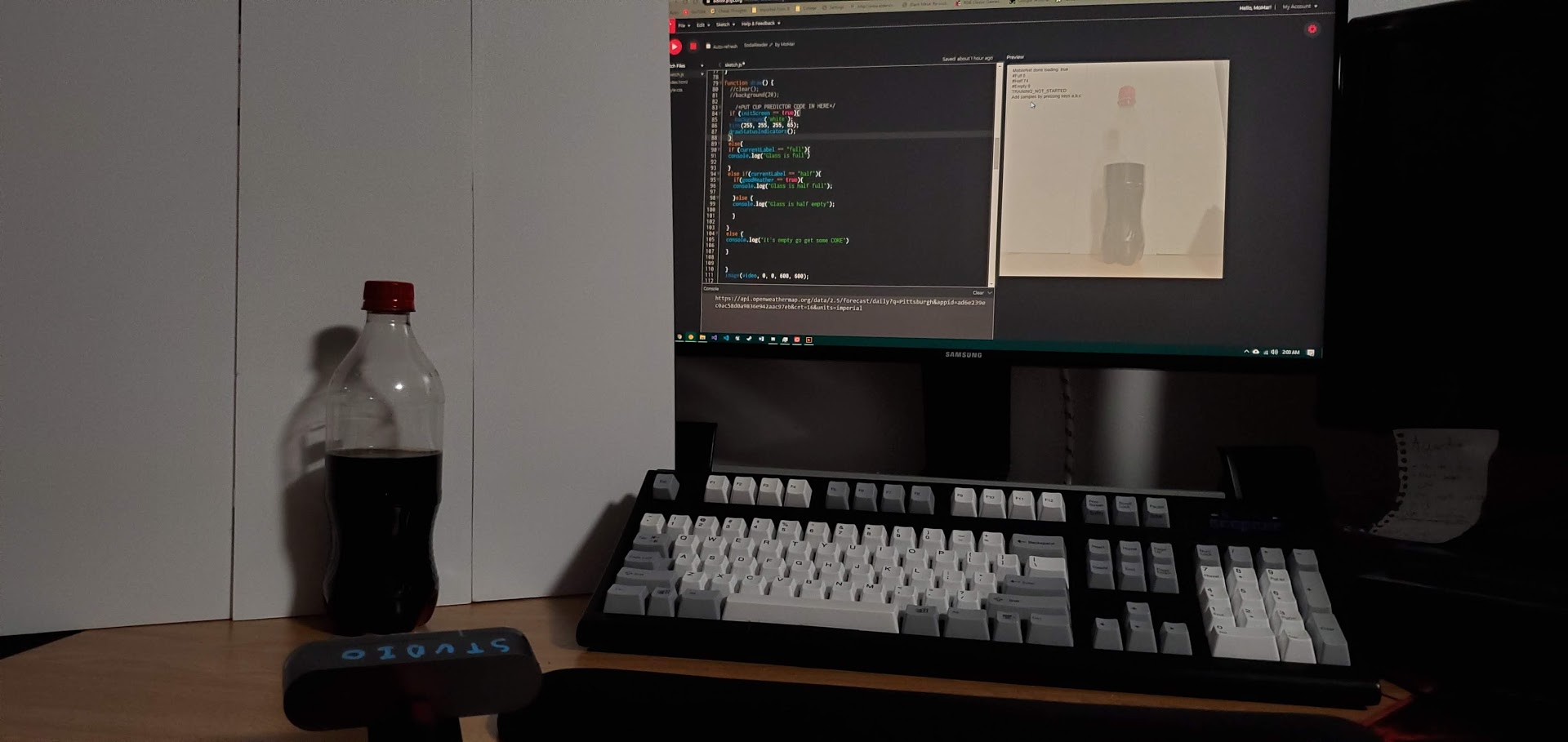
I actually used an example that didn't use p5js, because the example that I was using was not registering the poses properly when I was using it outside, and I had written my program around that example, so I just kept using it inside.
I first was going to use a raspberry pi or an arduino in conjunction with the browser, somehow?, and I tried a lot of different ways of doing that and got kinda close but it was just really complicated, so I actually used one of the worst hacks I've ever done. I got the browser to draw either a black or white square based on if someone was waving or not, and then I used a light sensor on the arduino to detect it and wave if the square was white. But if it works, it works, I guess.
PS. Sorry for the delay on this post.