Concept
In our studio desks, we have name tags differentiating which desk belongs to which design student. Another aspect of our studio culture is that we'd often leave notes, snacks, etc. for our friends. For example, when we know that a classmate is going through a stressful time, someone might leave a couple chocolates.
For my AR sculpture concept, I thought about using the name tags as an image target (since almost everyone still has theirs on their desks), and having this be a place where people can leave 3D presents for each other.
In this project, it was a rose.
(The original concept behind this was what if we had people leaving behind bouquets of flowers as a present? I wanted to do something where I used the "language of flowers" and had users put together their own bouquet of flowers (using flowers that convey the meaning they were hoping for), and leaving this on people's desks as a gift.)
As per our typical studio culture, we have a semi-public space, as anyone can see what is on our desks, but at the same time, this desk is our space. It is a common courtesy to not touch what is on it unless given permission to do so. Therefore, I decided to keep my application public, so that anyone with the app can see what someone has left on their desk. (No login factor.)
Development
For the server side of this application, I decided to use Firebase so that I could share the information across platforms (for anyone who has the phone).
However, I ran into a couple issues of getting Firebase to actually work. The biggest problem was getting the build to actually work, because I ran into an issue with CocoaPods, a library that has a universal dependency that was supposed to be automatically installed when building to Xcode...but did not...
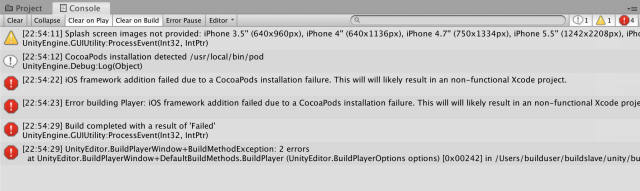
I know that Connie used FireBase for her project from last year, so I viewed her documentation (which was actually really thorough!) and looks like she ran into the same error as me:

And I tried doing the solutions she had listed out in her documentation, and had even found the same forum post she was referencing!
Alas... even after I directly installed CocoaPods to my computer using terminal, and double checked that it was actually in my Finder, I was still getting the same error.
As for the actual interaction with the prefab, I wanted users to be able to add a gift for someone once they tap on the screen (if the image target has been recognized), but for some reason, it loads the prefab before I have even touched it...


It was actually sort of odd because sometimes it would show only the original prefab, which is just the blue square, but then it would flash the rose prefab (that's supposed to only show after you touch the screen) immediately afterwards. I'm assuming this bug is coming from my code assuming that the user has touched when I have actually not..
// If user has touched
if (Input.touchCount > 0 && Input.GetTouch(0).phase == TouchPhase.Began){
Debug.Log("Touched!");
imageAnchorGO = Instantiate<GameObject>(prefabToChange, position, rotation);
I added a boolean and put it in Update() so it would run each time, but the entire app has been crashing... will look into this later.
Future developments...
Assuming I could get the Firebase server to work, I would've ideally wanted a function where users could add in their own present and gift (can pull from a database) and then compile it together. I think a future consideration would be thinking about how long the present should stay on the desk (maybe the owner of the desk can delete it themselves? This may require having log in information, etc, etc.)








 GANPaint Studio
GANPaint Studio