For this week's looking outwards on Physical Computing, it was super lovely and pleasant to re-stumble across Anti-Drawing Machine by Soonho Kwon (recent 2017 design graduate), Harsh Kedia and Akshat Prakash.
Anti-Drawing Machine was created using an Arduino, A4988 stepper motor drivers and custom enclosures, and code. It does exactly what it sounds like - it helps you draw - but also is opposed to you drawing. In other words, the machine allows for "disrupted or collaborative drawing by manipulating the rotation and position of an ordinary paper material. It exists at that very fine line between disruption and collaboration, trying to be both at the same time." I really adore this for not only it's interesting and complex ability to draw not only against the user's wishes but also with, in addition to it's playful elements.
This project is particularly engaging to me because it truly is an equal and dynamic dance between human and computer interaction. Without either side contributing their full effort, the drawing would not be what it is as it stands.
The Spirograph example on p5.js was one of the most particularly interesting to me because of its inherent complexity. The interlocking circles (sines), produce an interesting time system in my head, that reminds me of how our time definition works accordingly to the solar system, in that each large circle cycle could equal a year, each medium could be a day, and so on and so forth. Additionally, I found it even more mesmerizing when the underlying geometry was hidden, and instead, only the tracing remained.
One library that I found particularly interesting (as with what seems like the rest of the world is interested in now too, it seems) is the ml5.js library, or, the machine learning library. Not only was this one of the better documented and more user-friendly crafted library sites to view, it was interesting enough that it was marketed as "Friendly Machine Learning for the Web" -- and as a "neighborly approach to creating and exploring artificial intelligence in the browser", which made it not only extremely friendly, but made it feel as though machine learning would be the new ubiquitous thing.
"Friendly Words" is an interesting Block on Glitch -- it randomly generates a list of "word pairs" (which I feel are common for p5js web files), predicates, objects, team synonyms, team pairs, collection synonyms, and collection pairs. I thought this would be particularly helpful when generating random auto file names that have a bit of character for programs such as p5js and glitch, and/or random anonymous user names when entering as a guest into communal platforms (such as Google Docs).
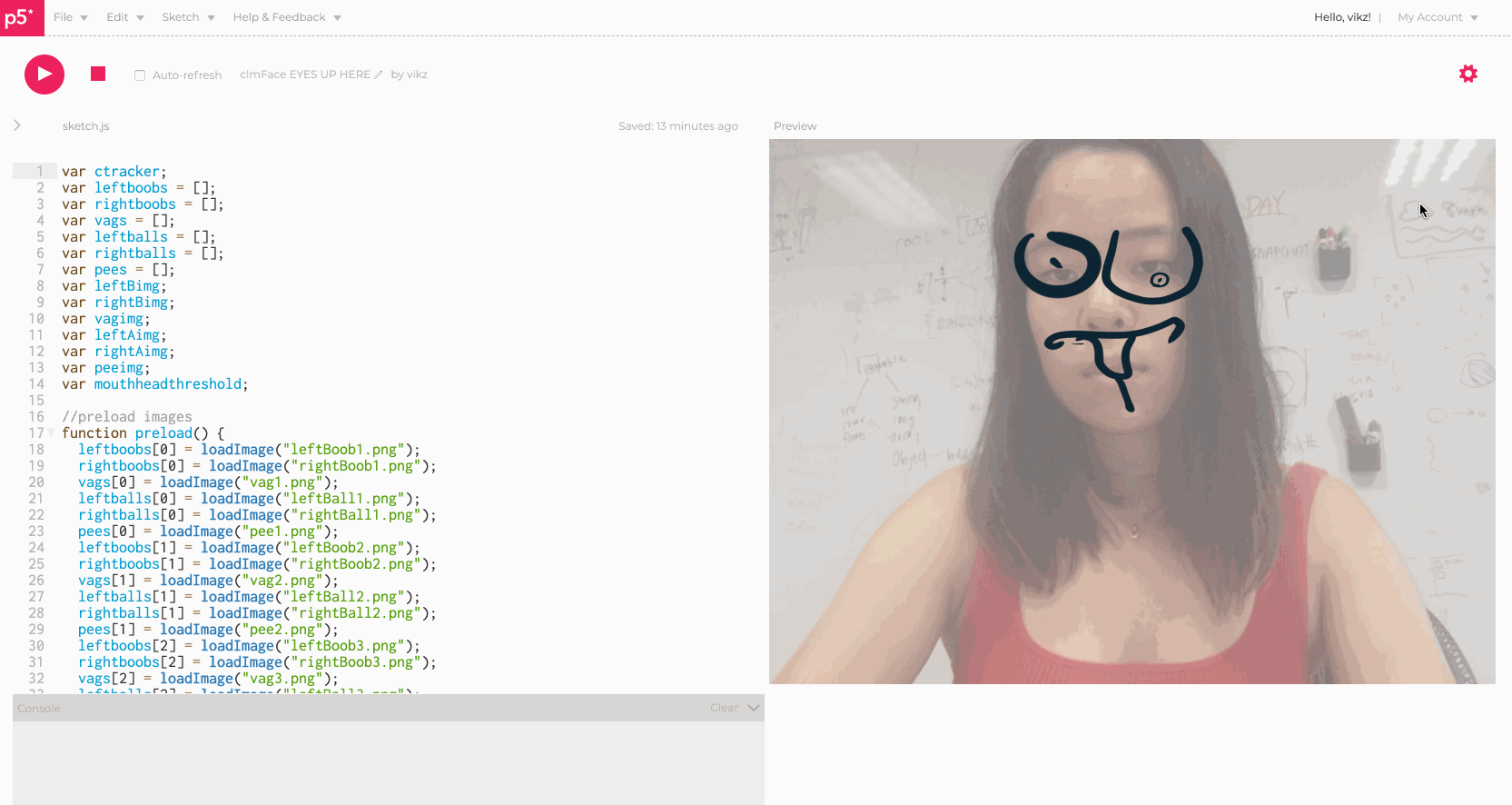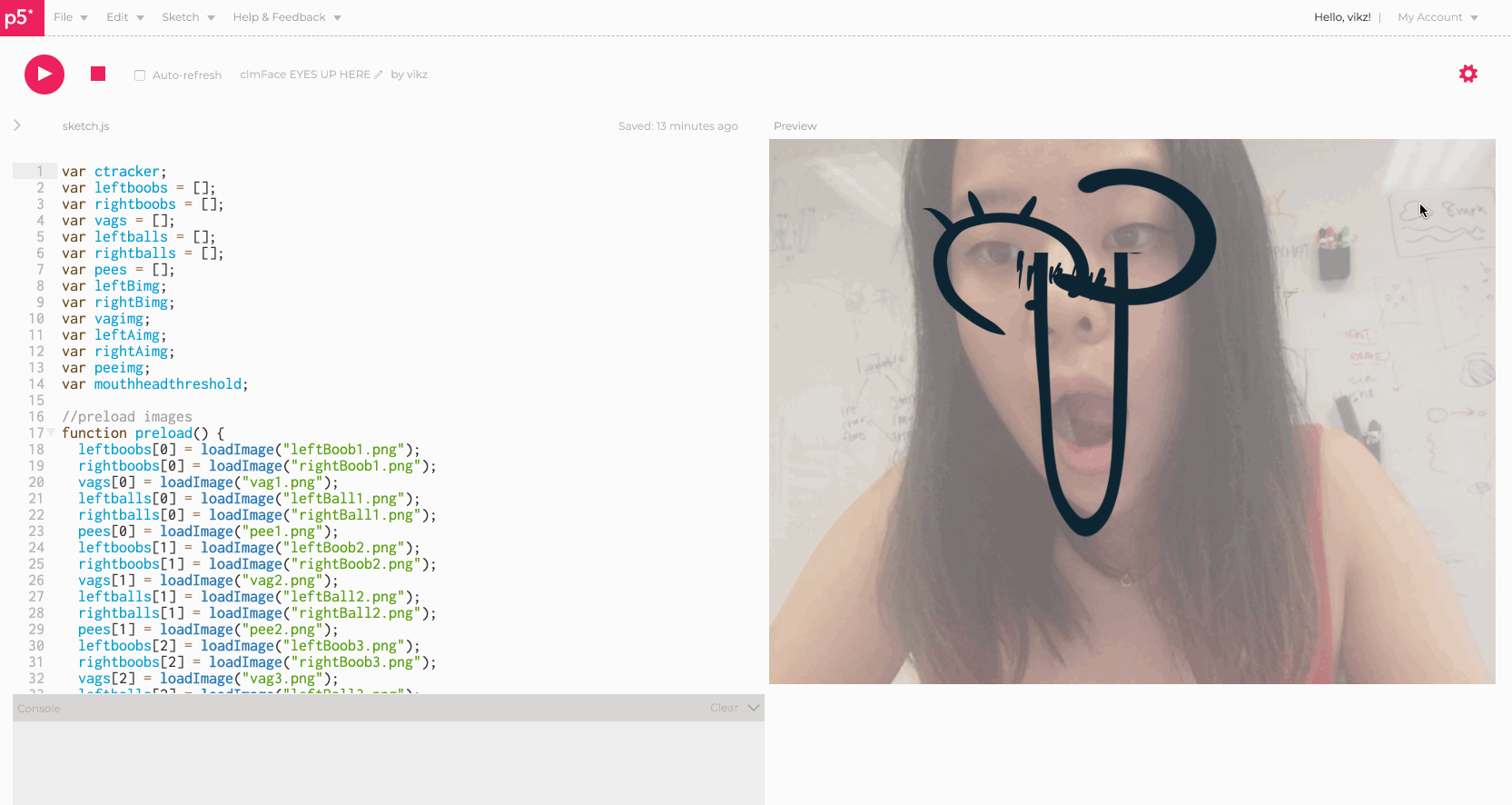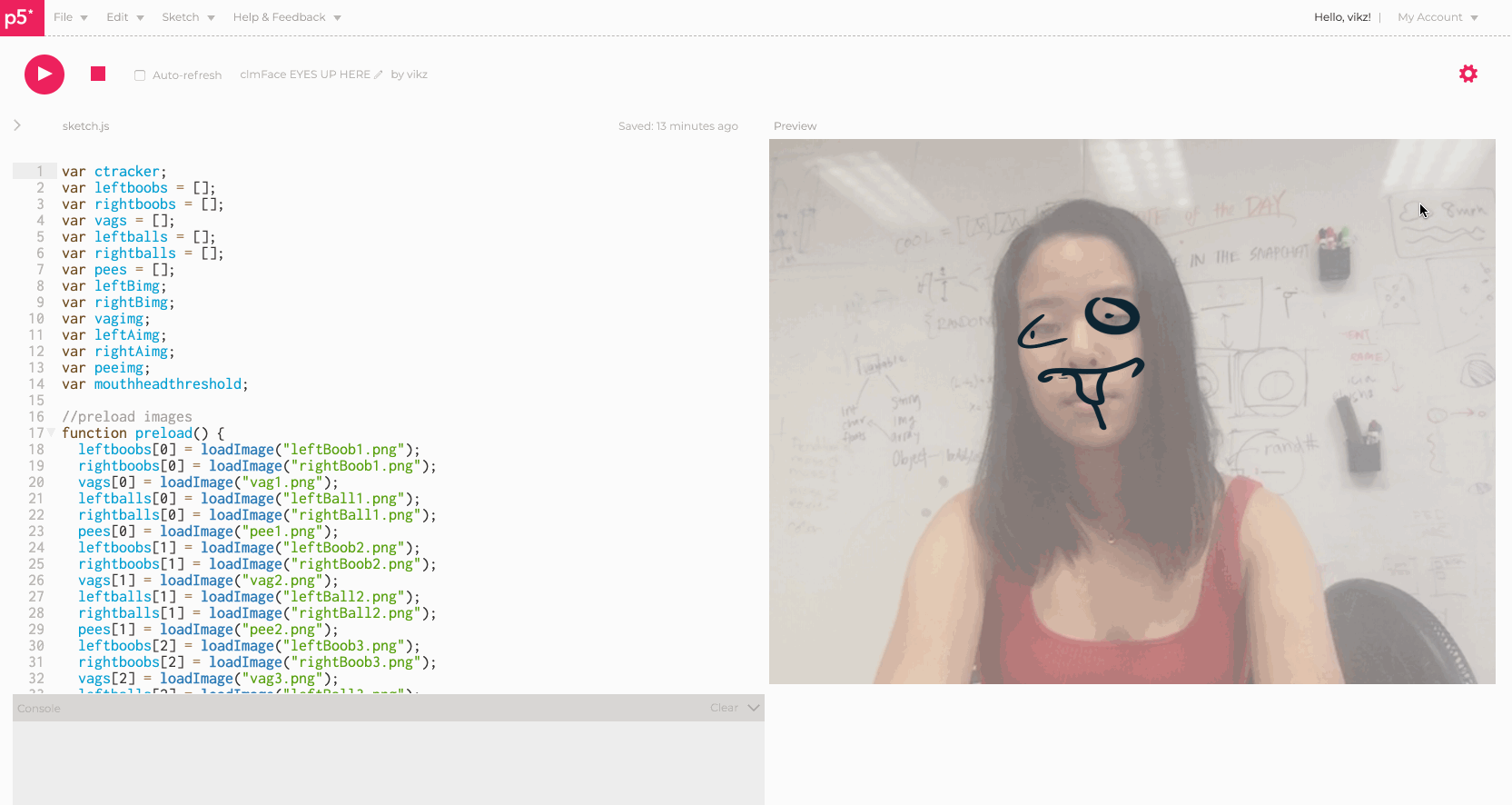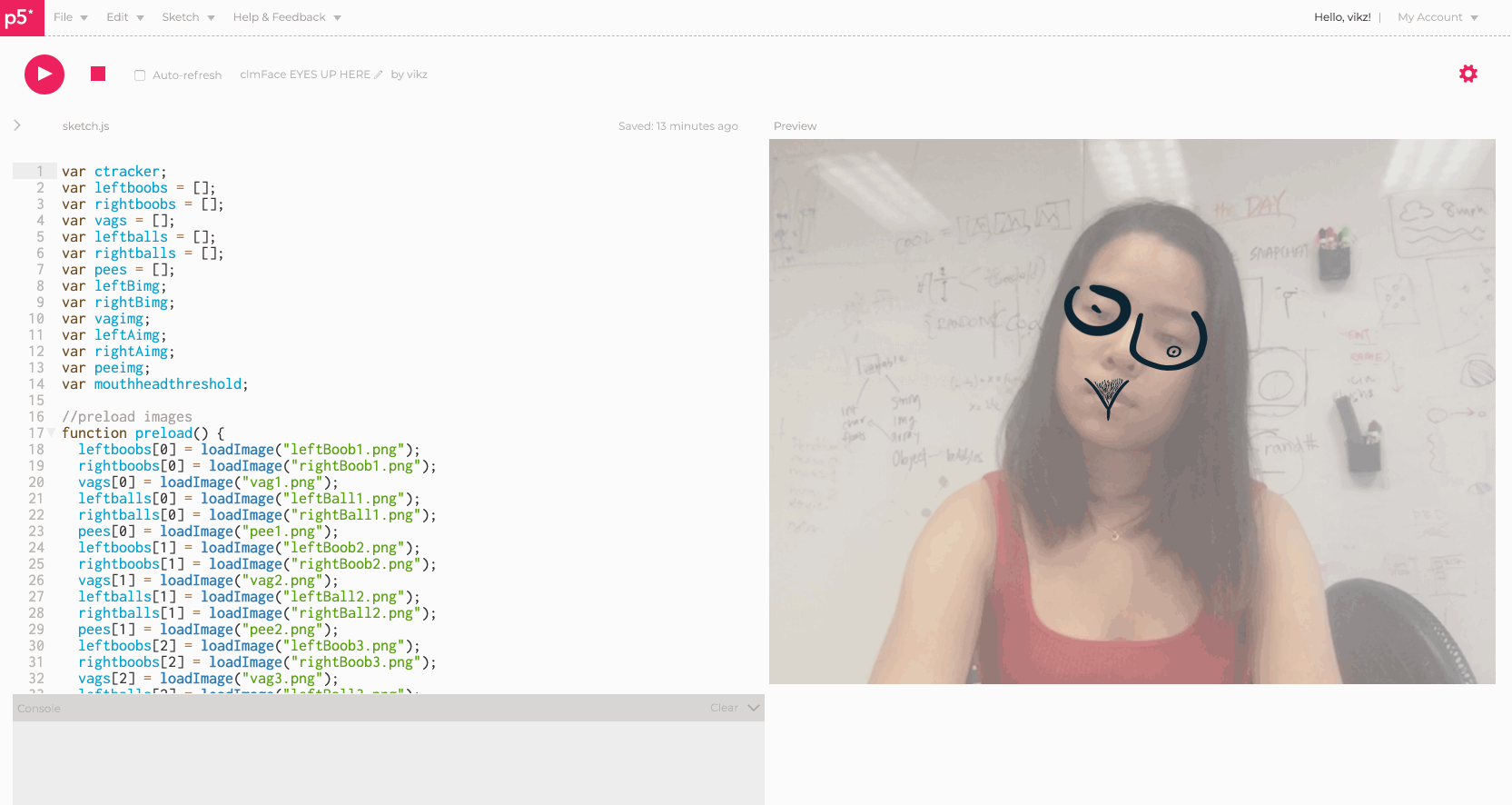
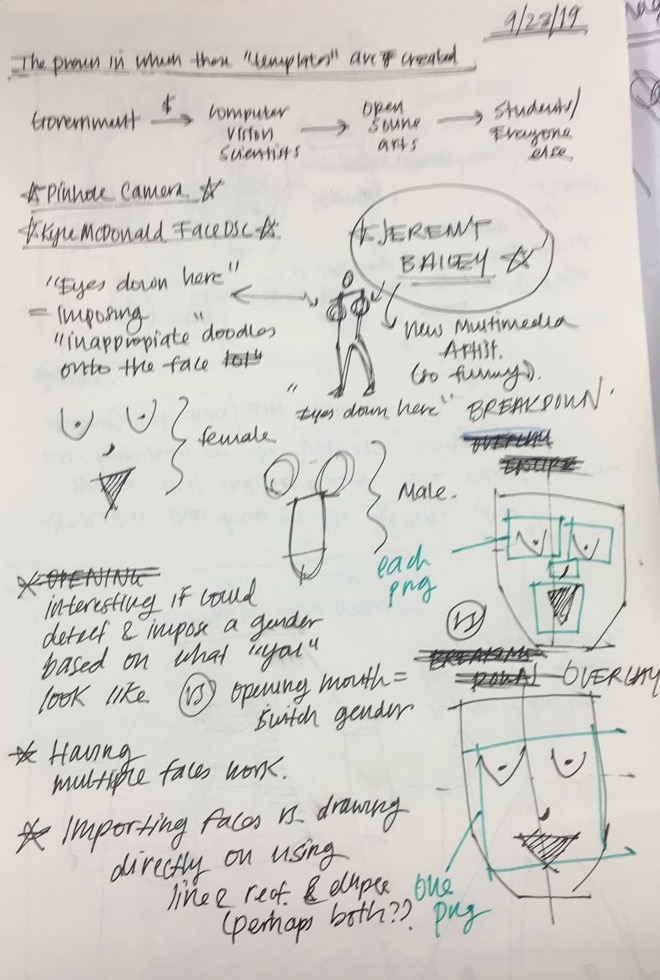
Eyes Up Here helps EVERYONE -- instead of just faking an obvious glance to someone's boobs while they are talking, why not just make it easier for us all and have the boobs shift right to the eyes? In fact, it would be a shame to stop right there -- Eyes Up Here allows ALL the genitals to move, right to the face -- talk about multitasking! Eyes up here, and boobs, and vaginas, and penises, and balls!
Click with your mouse to generate any of the vagina and boob pairings, and open your mouth to generate any of the balls and penis pairings. I had the most fun collecting sketches with my friends, and mostly struggled with implementing the images in a way that would scale accordingly and generate randomly.
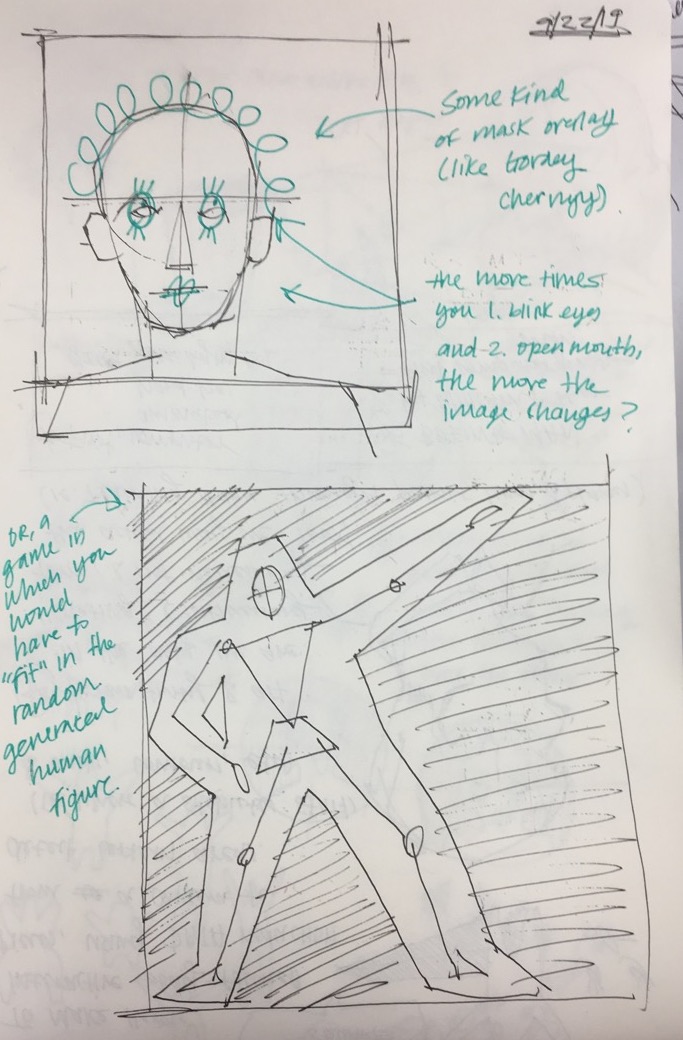
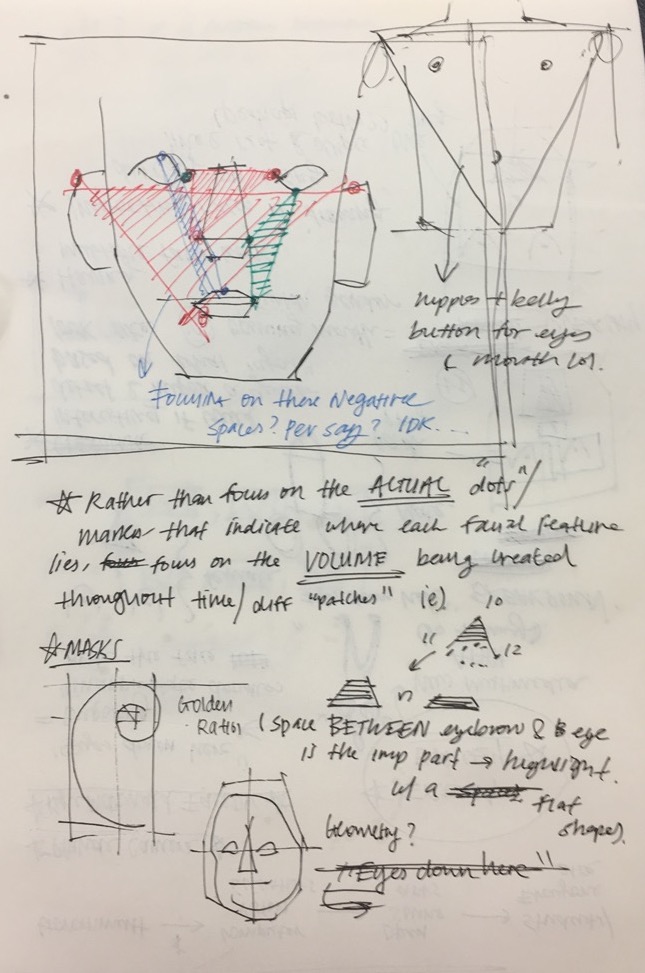
I had initially explored a breadth of ideas, including creating games in which one would have to fit certain facial parts within certain boundaries, and/or exploring the negative space between the different lines created when connecting different points on the face, however, I became particularly inspired by Jeremy Bailey's works. Also, I decided that many of those (initial) ideas would become poorly executed due to the natural gunkiness from the templates given, and I didn't have any strong vision that would make those ideas worthy of coming to life, aside from the inherent intrigue (ie. negative spaces, etc).
I am quite happy with the final outcome, as it was intended to be a more straightforward piece, and help me better understand the facial detecting mechanism. If I had more time, I would love to implement a system where users can draw their own doodles and have those become imposed on the face.
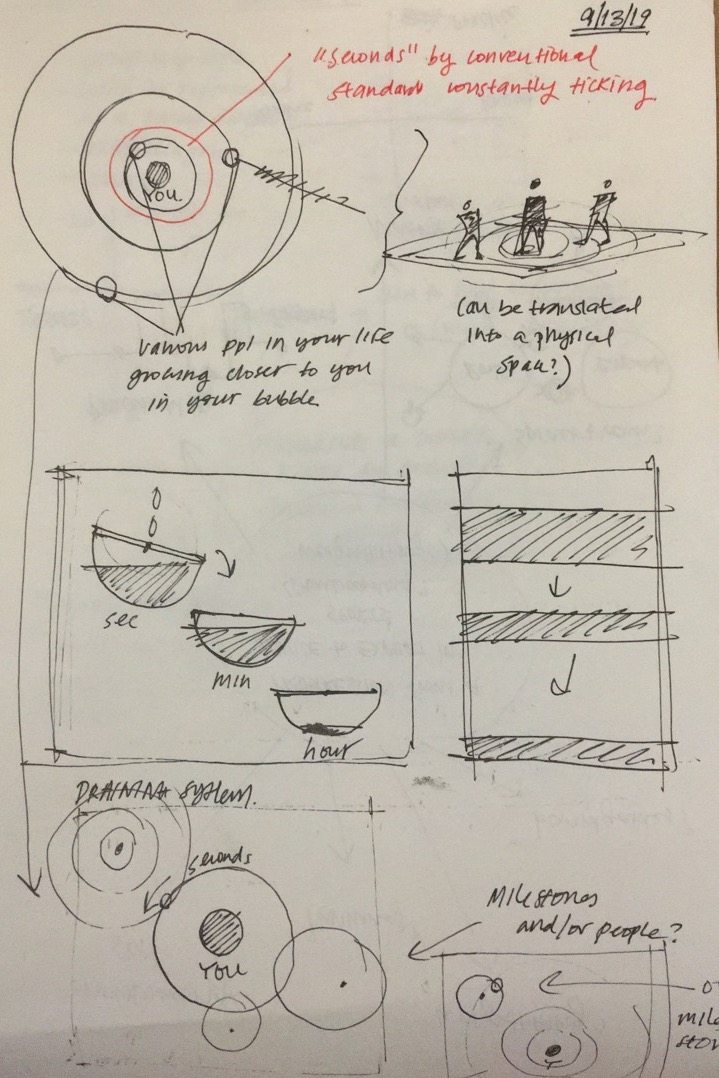
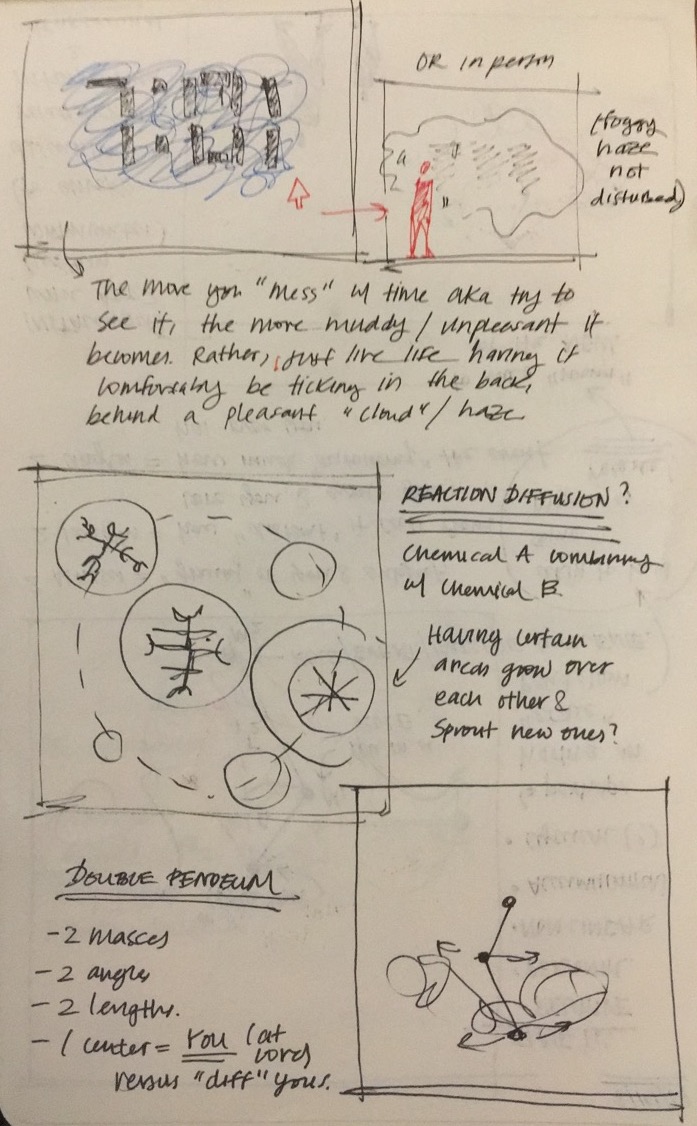
Initially, I had a large range of ideas that I wanted to portray in my clock - my "word bank" of ideas that I had included: time as something relative and personal, time as a "regulated" and measurable amount, linear vs non-linear forms of time, time as an accumulation of information/stories/ideas, and the juxtaposition of a personal journey of time with a societal construction of time. This led me to the idea of utilizing pendulums to represent the relativity of time to oneself in the various roles that one had in their lives, in juxtaposition to a "societal" construct of time (aka our 24 hour day). In this original idea, I had envisioned the center of a double pendulum "true you", the first mass stemming from the center your "role", and the second mass at the end of both pendulums as the "external factor". For example, my center would be "true Vicky", my first mass would be "sister", and my second mass would be "Allen" (my brother.) Another example would be "design student" as my first mass, and "Carnegie Mellon University: School of Design" as my second mass. Then, using my relatively perception of how I believed I was progressing or "moving", as an individual in that role, would influence how "crazily" that pendulum spun. The several "roles" I play in my life, however, would be juxtaposed with "societal time" as a pendulum that would move based on a 24 hour clock. I struggled a great deal and spent a large amount of time trying to figure out a class system of pendulums that would move at different accelerations, but managed to figure it out.
However, in the end, I decided to scrap the idea of having multiple random pendulums move at seemingly arbitrary hours, and instead opted for (to Golan's great recommendation), of having my double pendulums bounce randomly, but have it tell glimpses of real time if the first angle of the double pendulum pass by the correct "angle" at which that time were to be. When it does so, the pendulum highlights a bright orange, and marks the path a bright orange as well. For the rest of its journey, however, the pendulum path just follows a gradient of light blue to dark blue, on a loop of 60 seconds, to indicate when a minute has passed.
There was a great struggle in finding a way to have my clock tell the correct time, and I ended up having to manipulate my time so that the time I obtain from it (say 12:00), is rewritten as a different time (6:00), so that it correctly is displayed, because for some reason, my clock is mapped off. Additionally, the first angle in which it drops greatly varies the path that it follows, which is something that I would like to fix, as it hardly ever(?) goes to 12:00 when the first angle starts at PI/2, however, when set to PI, it swings rapidly and eventually skyrockets off into a lunatic acceleration.
"Halo" by studio Kimchi and Chips is a public installation of 99 robotic mirrors and a mist machine that resides in London, UK. However, the crucial element that completes the piece is the ever-changing sunlight throughout the course of the day. The mirrors follow the direction of the sun (like sunflowers), and the reflection of the light beams into the projected mist, ultimately creating a halo-like form - a form which "exists between the material and immaterial". It utilizes Bayesian inference machine learning in collaboration with unpredictable weather and natural forces to create a dynamic and ephemeral experience.
I find this installation particularly interesting because of how it is a superimposition of different timescales. Each moment is one different than the last, and reflective and reliant on the dynamic and independence of the sun, wind, and solar energy of the natural world. There is such an amazing juxtaposition and harmony of having such a robotic, machine like man-made structure with fine programming technology dance to the rhythms of nature.
For this piece, I thought it would be particularly interesting if I could play around the concept of having my frames be able to stand alone, but also seamlessly blend together to form a larger picture when stacked together. For some reason, I can't seem to figure out if I can embed pictures side by side on WordPress, so for now, my current example is how the gif interacts with each other when vertically stacked. Although my original sketch is not exactly what I created in the end (four circles that would follow a trajectory that could bleed into other squares) - I believe my new outcome was more interesting because of the functions I used (doubleExponentialSigmoid) and (elasticInandOut) from github libraries https://github.com/IDMNYU/p5.js-func/blob/master/lib/p5.func.js and https://github.com/IDMNYU/p5.js-func/blob/master/lib/p5.func.js. Frankly, so much of the time was spent trying to figure out how to alleviate the hiccups and create a GIF, so I know that much more time could be put into creating a more "seamless" flow between the different GIF frames, as there is some sort of hard line where one frame ends and the other starts.
"First Word Art" and "Last Word Art" are both terms that I have been exposed to before, and my general stance that I continue to take is that both can be considered as "true art". I strongly disagree with the stance that "first word art" is not considered art, because I do not believe that mastery has to take place in order for a piece to be considered "art". Rather, I believe in that art can take an exploratory nature and serve as a catalyst for other movements and/or works; to me, this sort of effect serves an even greater purpose.
I believe my interests lie more so within the realm of "first word art". Rather than create the "ultimate" perfected piece and/or artwork of a certain sort of style, I much rather enjoy exploring new concepts that may inspire and provoke others. I enjoy seeing the possibility of extension and further exploration that could ensue after my work, rather than my actual final work, at times.
Although we aspire to make things of lasting importance, many times our creations do not age well. Many times, this could be a result of not designing and/or creating for the future without future-design thinking in mind. From a design standpoint, Jamais Cascio's three main critiques for designing for the future can be applied here: 1) Does my scenario and/or product focus only on technological advances and miss the day-to-day of everyday life, 2) Does my scenario assume everything will work and miss the possible failures and unintended uses and 3) Does my scenario only focus on the dominant classes and ignore the broader impacts of society? When considering future works incorporating novel technology, we can often fail to consider our work these lenses, consequently failing in creating things of endurance and longevity.
Nature and biological life are systems that serve as exemplars to effective complexity, and so dandelions were what first came to my mind as one of my favorite instances of such. On the spectrum, I believe dandelions fall within an equal split between relative order and randomnesses, which is why I feel particularly drawn these weeds, as I am fascinated with the balance and similar distribution of both. Typically, dandelions can be associated with having extreme "randomness" -- pick up the flower, blow on it, and have the seeds scatter haphazardly over the field by dancing, lifting, and dipping from the wind. However, once each individual seed settles, there is a method to which biological processes will take place from there -- depending on the fertility of land, the seed will take root, germinate, bloom into flowers, and repurposed into white pappis with seeds at the end. Additionally, dandelions are capable of asexual reproduction, resulting in many identical flowers. Wind and/or other factors in nature then chaotically disperses of the seeds, and the cycle continues.
1B) The problem of Meaning: Can and should generative art be about more than generative systems?
Generative art serves as a medium to help maximize the possibilities and skillsets of an artist. However, to this, arises the issue of whether or not the emphasis should be placed on the "generative" or "art" aspect. Some projects call for attention to be drawn to the multiple iterative art pieces as the final product (with little regards to the process in which went about creating them; a top down approach), whereas others highlight the system of creating generative art (with little regards to the byproduct itself; a bottom up approach). Although there lies value in both approaches, I find myself personally aligning with the values of bottom up. Typically, when I finalize my mind on exactly what an end desirable should exhibit, I find myself more "comfortable", in the sense that I have a working goal in mind and am more so simply seeking the bridges to connect me to that. Whereas, when I work from a bottom up approach, I find it more rewarding to "seek truth to process as being inartistically beautiful", which not only celebrate creation as an activity, but also allows me to maintain an open mindset, and ultimately, design and create emotionally durable experiences.
Face Trade is a vending machine of sorts -- cash in a portrait mugshot of yourself (taken on the spot at site), in return for receiving a computer generated face drawing. Your mugshot that Face Trade receives will then be permanently stored in the Ethereum Blockchain, therefore suggesting the exchange of a "semi-permanent" face-swap. The Face Trade project is comprised of a printer, thermal printer, buttons, lcd screens, speakers, cameras, flash, MDF, steel, paint, computer, and website. There is no information as to how Moka has decided the algorithm to which produces the unique generated portraits, and it is also not explicitly stated if there is a a feedback mechanism to which the mugshots help generate the unique portraits. However, I would think that there would be some sort of initial face detection code to pinpoint key components of a face (two eyes, a nose, a mouth, etc.), and then a library to which these faces would be generated from. From this, I suspect that there could be a machine learning element in which new mugshots retrieved could play a significant role in generating new eyes, noses, and so on and so forth.
I enjoy this project because of the union of inputting a personal stake and receiving an unique surprise. Moka "often trades control in favor of surprise" because of his belief of computation as an expressive tool. The effective complexity of this project is 50% balanced order and 50% disorder - the user has half of the power to generate the end deliverable; they have the complete choice to input whether or not they want to "cash in" and the deliverable (an unique portrait), however, they have no say as to how their mugshot will be used thereafter and what their unique portrait will look like.
There is an overall flow to the image (having majority lines flowing either upwards/downwards, or flowing left/right
Most lines are either touching one another or intersecting
Lines near areas of negative space can be found to not touching other lines
Many areas have repetitive lines "patterns" of some sort, with slight change of angle from one line to the next.
Negative spaces between normal touching lines have relative similar area.
There are random patches of absence of lines ("interruptions")
Negative spaces "interruptions" are no more than 30% of the space.
There are almost "columns" / "rows"; each line going down and across seem to have the same center point
Amount of lines in each "column" / "row" ranges from roughly 45-55 lines.
Process: Originally, I had wrote three main functions (one to generate the lines themselves, one to generate a grid for which these lines would be placed, and one for calculating random holes based on noise(), to which I would then use in regards to the grid + line functions. I had run into several issues with this way, as I struggled manipulating each individual line to rotate in more "random" ways - it came down to either rotating all the lines at once, or rotating the entire canvas. I then decided to build off of Dan Shiffman's Coding Challenge #24, to which the manipulation of identical length lines were achieved through creation of a vector variable (p5.vector.fromAngle), to which he was then able to manipulate solely the vector itself by calling a rotation directly onto the vector, rather than the entire canvas. Then, through a noise function, I was able to achieve allotting "holes", or gaps in the canvas.
Although Dan Shiffman's way was very neat in achieving a series of segmented lines, I would have been more satisfied if I were to have the time to debug my own separate three functions. I believe that I would be able to achieve similar results if I could translate the way I drew lines by calling a vector, and then directly calling onto the vector to call for a rotation.